Here is a new project, when can you finish it?
You are a seasoned software engineer. You have plenty of projects under your belt. With that kind of experience you should be able to tell when this brand new project will be finished….
Three are a couple of things to consider here. One is that engineers almost always under-estimate. But knowing this is not all that useful, as there is no solution to it. You can pad your estimates with an additional 25%, 50%, 100% and they will never be right… not sure why that is… possibly when we pad our estimates we sub-consciously also increase the amount of work to be done? Not sure.
What *is* more helpful is to know that at the start of any large project is when we have the maximum uncertainty about the project and when we will complete it. Over time as we work on the project, the uncertainty decreases. This is known as the Cone of Uncertainty. 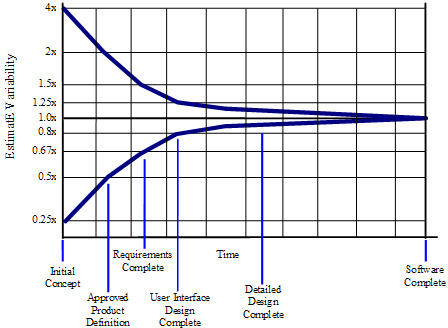
[Cone of Uncertainty — Construx]
The cone of uncertainty was popularized by Steve McConnell (he wrote Code Complete) who is pretty much a waterfall guy (the x-axis for the cone above indicates this). I would rather direct you to an agile solution here. This is where Real Scrum comes in handy. Real scrum has the following
- A Product Backlog with user stories: As a <someone> I want to <something> because <some reason> — each one describing some small increment of potentially shippable product
- A Product Owner who understands the vision of the product and works with the engineering team to prioritize and estimate those stories in the product backlog
- Estimates for the user stories that are unit-less — in Story Points
- Sprints of duration of about 2 weeks
- Sprint planning to create a sprint backlog for these sprints. Sprint backlogs are actionable tasks for the team to implement.
- Sprint retrospectives where the sprint velocity is calculated, and improvements made to the process
It may seem like I am just spouting off a Scrum handbook, but each of these items I wrote is CRUCIAL for you to be able to accurately estimate your deliverables. Remember, you really have little idea of when the project will finish when you are first told to estimate it, but using Scrum then only 2-3 sprints into the project you should have a much better completion estimate. Here is how the above bullet items get you to a great estimate.
- Product backlog user stories are prioritized so the most important items get worked on first
- Product backlog user stories are estimated in story points — humans are MUCH better at relative estimates (this is 2x that) than absolute ones (this will take 3 weeks)
- Over 2-3 sprints you will learn how many story points you can complete in a sprint — this is your velocity
- Given your velocity you now know how many sprints it will take to get to a certain point in completed user stories from your product backlog (you have a date when all the P1 stories will be complete, you also have a later date when ALL the stories will be complete).
- As you iterate more, and as you complete more, you will have a better idea of completion dates
Also note that Scrum must also include a Demo after each sprint. Here you will get feedback from stakeholders, which will better inform the contents of your product backlog, and help you deliver the most customer-centric product possible.
And that is how Real Scrum can help you to estimate when you can deliver that new project.












